The Top of the AI Pyramid: Machine Learning Prompt Flow


The Top of the AI Pyramid: Machine Learning Prompt Flow
This article is written by Onyx Data Senior Consultant – Dennes Torres
In this article, let’s put all the pieces together for LLM solutions and discover what is Machine Learning Prompt Flow, how does it work, where it lives, what does it eat?
What’s RAG
RAG stands for Retrieved Augmented Generation. In summary: This means to make the generative AI models, in special LLMs, work with your company data.
You will find lots of methods to achieve this around the web, but most of what you will find are for specific scenarios.
These methods have a lot in common:
- Usually, they make a vector index of the information to be searched. This vector index is also called Embeddings and can be creating using the Text-Embedding model on Azure Open AI.

- The full text index plus the vector index is usually stored in Azure AI Search, also called Cognitive Services Search. The vector is an additional field in the AI Search index

- The LLM model uses the information from Azure AI Search to provide the answer we need.
- The process used by the LLM model could be implicit (Azure Open AI is capable to do it) or explicit, when we generate the embeddings, make the search and provide the results to Azure Open AI.
- The explicit process involves creating embeddings from the user question, searching these embeddings on Azure AI Search and returning the result to the LLM model. The LLM model will work over the result provided by Azure AI Search. This explicit process is used only on Azure ML Prompt Flow.
- Bots were rebranded as CoPilots, but they continue to have a fixed question/reply structure, not as intelligent as an LLM

- The new feature CoPilots brings to the table is the integration with LLMs a.k.a. OpenAI, but this built-in integration is limited and I would say intended for smaller companies. Bigger companies will need custom integration.

It seems a bit messy, doesn’t it?
The many methods to reach similar results, but always with some limitations here or there makes the scenario a bit messy.
Machine Learning Prompt Flow to the Rescue
It came to put order in the chaos. It rules over all other methods.
ML Prompt Flow is a workflow system which allow us to orchestrate LLM, AI Search and Python tasks to reach our main goal with a single product, instead of building different products, each one to reach part of your goal.

There are so many possibilities about what we can do with this kind of orchestration that I need to confess: My creativity fails when trying to think about scenarios for prompt flow implementation.
I don’t think it’s only my creativity: Most examples I find in relation to prompt flow end up being some kind of classification example, which is not much different of what could be done with other machine learning algorithms.
The only thing new on the examples I saw was the possibility to get the company data on the fly and feed to prompt flow. No previous index created, everything done on the fly.
Let’s try to unblock our creativity. In order to do that, I will introduce to you LISA. Let’s analyse what LISA can do and specially what it couldn’t do and how Machine Learning Prompt Flow solved this problem.
Meet LISA
LISA is an LLM system built by Onyx Data and me. We made it publicly available and it’s capable to query structure and unstructured data. On the unstructured side, we feed LISA with information about Microsoft Fabric and Data Platform. We use the articles we write to feed LISA, so it can answer technical questions and maybe even help on the DP-600 exam.

Mind when I say “system”. It’s not only about getting an LLM, throw a prompt over it and it’s done. LISA is based on more complex concepts and needs.
Let’s check these concepts:
- You need to feed an index with your unstructured data. That’s where AI Search fits. We also need a backend portal which allow us to control the AI Search indexes, adding new information, either from documents or from the web, and removing information we don’t want there anymore.

- We can’t expose an LLM directly to our end user. An LLM is unpredictable. That’s where the
Bots(oops!) Copilots, comes into play. The Copilots allow us to define fixed answers to specific questions and subjects, allowing us to control what our Copilot will tell the user. When the user goes out the scope of answers of the CoPilot, a Power Automate Flow is called, to trigger the LLM backend.

- When I say “LLM Backend”, I’m not talking directly about Azure OpenAI. When calling Azure OpenAI we need to send a set of configurations, including configurations which tells OpenAI which index should be used to get the information context to answer the query, plus the prompt we would like to use at that moment. In order to put all these configurations together, we use an Azure Function to call the Azure Open AI API with everything set.
- The Azure function not only ensures the correct input to the LLM, putting the configuration together, but also fine tunes the output. Small details, such as reference to source documents, sometimes requires small fine tunning and the function does that, returning to the Power Automate flow a ready to use reply.
This is the LISA architecture for unstructured data:

All this I just mentioned is half of LISA. This is the half which deals with unstructured data. How could we deal with structured data?
LLMs and Structured Data
There are 3 methods to deal with structured data:
- Index the structured data together the unstructured data in AI Search. The LLM will search everything in the same way.
- Provide small datasets to the LLM as part of it’s prompt.
- Teach the LLM what’s the modelling of the structured data, allowing the LLM to build queries in the source language (SQL for example) to retrieve the data to answer the question made.
There is no common answer about which one is the best solution. What I can provide is my opinion:
- If we put structured and unstructured data together, the LLM may fail in finding relationships between different pieces of the structured data, not providing the quality of answers we would like to have. We lose in quality but get the benefit to have a single prompt to answer questions about both types of data. I don’t think the quality loss worth it.
- A single dataset is great for showbiz, magic tricks and to make the audience says “Uau!”. However, a single dataset neither allows the LLM to have a view of the entire data model nor allow the LLM to analyse big amounts of data, because the prompt has a limited size.
- If we explain our model to the LLM, the LLM can generate the query to answer our questions. However, this leads to a different prompt for the structured data (different than the unstructured one) which ends up leading to a different UI. There is the risk that a too complex question, which would need more than a single query to be answered, would fail. However, my creativity didn’t manage to create such question yet.
Our public LISA deployment uses the 3rd method. You may notice on the site you can talk to LISA on one window, asking questions about Onyx Data and Data Platform in general, or you can use the other window to ask questions about the NUTS geography model and getting datasets as results.
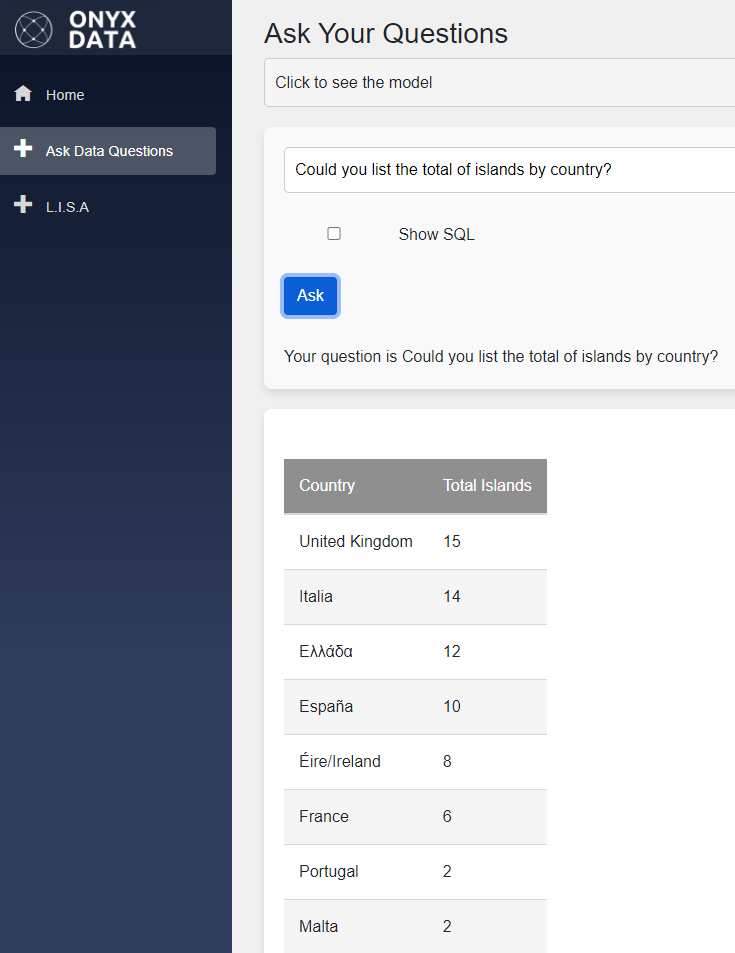
NUTS means Nomenclature of Territorial Units for Statistics. We imported the NUTS data into a Microsoft Fabric Lakehouse and implemented the 3rd method, explaining to the Azure Open AI the structure of the data.
This is the architecture of the structured part of LISA:

This 2nd window uses the LLM to generate a SQL query and executes the query over the model which is in a Microsoft Fabric Lakehouse.
The ML Prompt Flow Challenge
Considering the architecture I explained above for LISA, the Prompt Flow challenge is to unify the flow of both sides of the architecture: The unstructured architecture and the structured architecture.
Unifying both architectures, we become capable to use a single Copilot to ask questions about both kind of information, structured and unstructured, and get a clear reply about it.
Is the Machine Learning Prompt Flow up to the challenge?
Well, if I’m writing these lines, that’s because I successfully proved it is.
The Prompt Flow Architecture
The flow starts with the input from the user on the chat. In our sample scenario, what’s our first challenge?
We must identify if the question of the user is about Data Platform – our unstructured set of data – or it is about the European countries described on NUTS, our structured source of data.
The best way to do that is asking it to Open AI. We will not ask at this moment to answer the user question, we will ask to classify the user question so we can decide which part of the flow will be executed.
If the question is about structured data, we can follow this sequence:
- We ask the LLM to generate a SQL query to retrieve the data to answer the question. This time we will build a prompt explaining the relational model.
- We use a Python block to execute the SQL against the data source, in our example, a Fabric lakehouse.
- We get the data and send again to LLM. This time we ask the LLM to answer the user question based on the context we are providing. The context, in this case, is the data result of the SQL execution.
- The result may be considered better than the original one: Instead of a cold table of data, we get an explanation of the result.

On the other hand, if the question is about unstructured data, we can follow this sequence:
- We use one prompt flow activity to create embeddings for the question of the user and search the question inside Cognitive Services. Differently of what is provided by the Azure Open AI API for c#, for example, the search in cognitive services and the submission to the LLM happens in different stages.
In fact, just a few weeks before I’m writing this and in all current walkthroughs and documentation in Microsoft portal, this is an evolution. All the walkthroughs, including the templates in prompt flow, make this in more steps. First create the embeddings for the question, then search the embeddings on the index. These activities became deprecated and replaced by one to execute both tasks together.
- We use the result of the search to prepare a prompt for the LLM. There is an activity specially to help us build a prompt.
- We call the LLM with the prepared prompt to answer the question.

The Deployment
The ML prompt flow has a managed deployment, which is like machine learning model deployments. It creates virtual machines, but you don’t need to manage them, the endpoint deployment will manage them for you.

The deployment provides an API endpoint which you can call from the Power Apps flow, returning to the beginning of the architecture. This time, instead of the Power Apps flow calling an Azure function directly to access Azure Open AI, it calls the ML prompt flow. The function call is part of the flow.

As the result, we now have a single chat UI capable to answer information from structured and unstructured data.

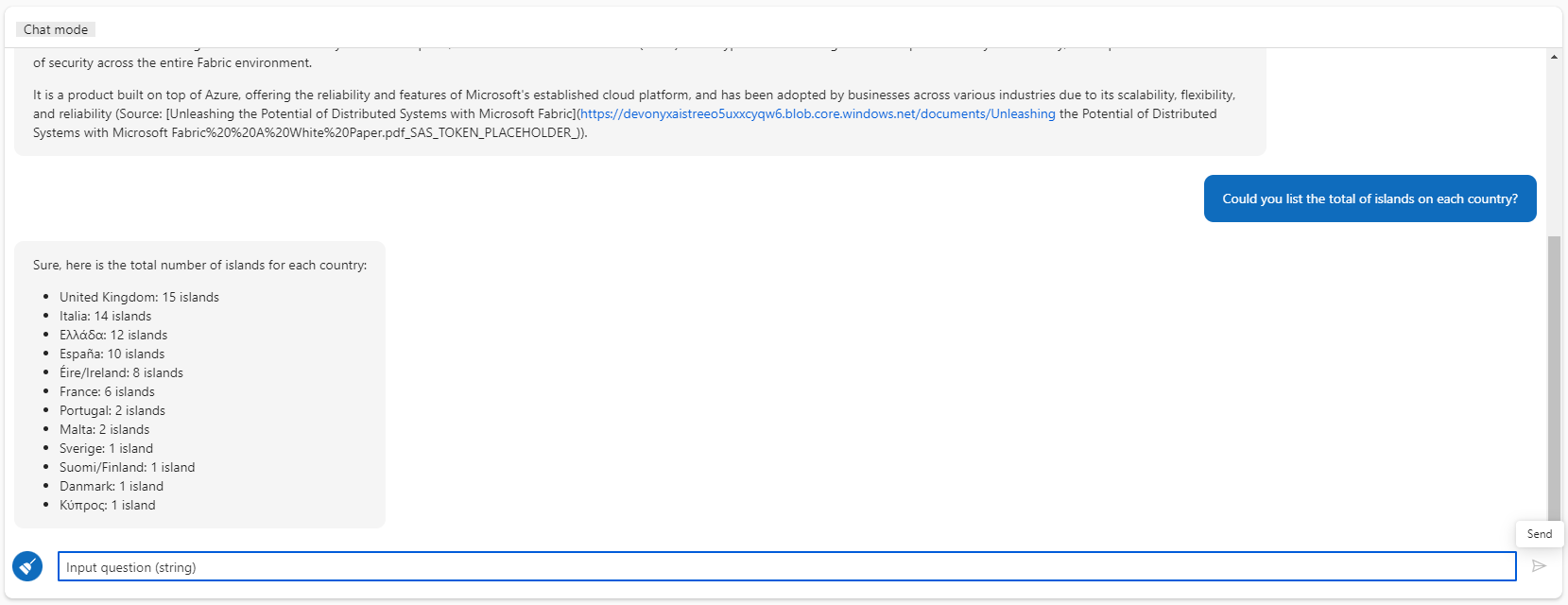
Your creativity is the limit
I used prompt flow to join two different architectures in one, resulting in a single CoPilot and a more powerful RAG for the company.
How do you plan to use prompt flow?
All this architecture I explained is only the top of the iceberg. Prompt Flow is capable to accept files as inputs.
Currently, the files are announced to be used for vision AI, image handling and generation. However, I don’t see anything forbidding you to upload a JSON, CSV or other format which Python can read, process and submit to the LLM.
The next steps is a walkthrough to better understand the technology.
Related Articles


