Beginner’s Guide on Azure Data Engineering — Series 1

Azure Data Lake Storage Gen 2 Account Set up
Azure Data Engineering is the discipline of designing and building scalable, secure, and performant data pipelines using Microsoft Azure’s cloud ecosystem. It covers the end-to-end journey of data: from ingestion to transformation, storage, and finally consumption — enabling organizations to turn raw data into actionable insights.
It forms the backbone of modern data-driven systems, supporting use cases such as business intelligence (BI), machine learning (ML), advanced analytics, and real-time reporting.
Core Responsibilities of a Data Engineer on Azure

A data engineer working with Azure typically handles:
- Data Ingestion — Collecting data from various sources (databases, APIs, IoT devices, flat files, etc.)
- Data Storage — Storing data efficiently using structured, semi-structured, or unstructured storage systems.
- Data Transformation — Cleaning, reshaping, and enriching raw data into business-ready formats.
- Data Orchestration — Automating workflows using pipelines and scheduled jobs.
- Data Integration — Combining data from different sources to create a unified view.
- Performance Optimization — Ensuring queries and pipelines run fast and at scale.
- Security & Governance — Applying role-based access controls, auditing, and compliance policies.
- Data Serving — Delivering data to downstream systems like Power BI, ML models, or third-party tools.
Key Azure Tools for Data Engineering

Modern data engineering on Azure is powered by a suite of tightly integrated services that cover everything from data ingestion and storage to transformation, analytics, and visualization. Below is a detailed overview of the most important tools and their real-world applications:
Data Ingestion & Orchestration
- Azure Data Factory (ADF) — ETL/ELT pipelines across on-prem/cloud data sources.
- Azure Synapse Pipelines — Orchestration similar to ADF within Synapse workspace.
- Azure Event Hubs — Real-time streaming ingestion from apps, websites, and IoT devices
- Azure IoT Hub — Ingest telemetry data from IoT devices.
- Azure Logic Apps — Workflow automation for integrating data across systems.
Data Transformation & Processing
- Azure Databricks — Apache Spark-based platform for big data transformation and machine learning.
- Azure Synapse Spark Pools — Distributed Spark engine within Synapse for transformation and notebooks.
- Azure Data Lake Analytics (U-SQL) — Scalable analytics using a SQL-like language (legacy tool).
- Azure Stream Analytics — Real-time data processing using SQL-like query language.
Data Storage
- Azure Data Lake Storage Gen2 (ADLS Gen2) — Scalable hierarchical storage optimized for big data analytics.
- Azure Blob Storage — Object storage for unstructured and semi-structured data.
- Azure SQL Database — Managed relational database for transactional workloads.
- Azure Cosmos DB — Globally distributed NoSQL database for massive scale.
- Azure Synapse Dedicated SQL Pools — Data warehousing storage for structured data.
Analytics & Visualization
- Azure Synapse Analytics — Combines big data and data warehouse capabilities for analytics
- Power BI — For creating reports and dashboards from transformed/clean data.
Governance, Security & Monitoring
- Azure Purview (Microsoft Purview) — Data catalog and governance platform.
- Azure Monitor & Log Analytics — For monitoring pipeline health and infrastructure.
- Azure Key Vault — Manage secrets and credentials securely.
- Role-Based Access Control (RBAC) — Secure data access and resource permissions.
Developer Tools
- Azure DevOps — CI/CD pipelines, Git repo integration, infrastructure-as-code.
- Azure CLI / ARM Templates / Bicep — Infrastructure automation and resource provisioning.
- VS Code Extensions for Azure — Local development for Data Factory, Synapse, and more.
Project Guide for Beginner
Before we dive into Azure Data Engineering, it’s important to lay the foundation by setting up the essential resources we’ll be working with. In this guide, we’ll start by creating a Resource Group, followed by provisioning Azure Data Lake Storage and Azure SQL Database — the core components we’ll be using throughout our project.
Let’s begin with the Resource Group. Think of it as your workspace — a container that holds all the Azure services and objects related to a specific project, making them easier to manage and monitor to create one:
Head over to the Azure Portal, search for “Resource Group”, and click on Create to get started.
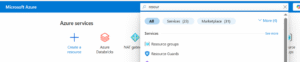
Use the image below as a guide to set up your Resource Group — be sure to select the correct subscription, provide a meaningful name, and choose a region that is geographically close to you for better performance. Once done, click Review + Create to finalize the setup.
All the resources we’ll be creating going forward — including storage accounts, databases, and data pipelines — will be organized under this Resource Group, keeping everything neatly grouped for easy management.
After creating the Resource Group, the next step is to provision a Storage Account — this will serve as our landing zone for ingesting and storing raw data.
You have two options for creating additional resources in Azure:
- Use the Resource Group blade to add new resources, which will redirect you to the Marketplace.
- Or search for the resource directly from the Azure Portal homepage.
In this case, we’ll go with the second approach.
Search for “Storage Account” in the Azure Portal search bar. Be mindful when selecting from the results, as several storage-related services may appear.
Once you’ve identified the correct service, click Create, and proceed to set up your Storage Account using the image below as a guide.
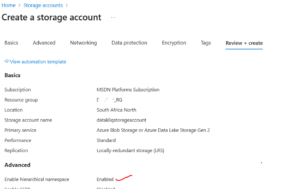
You’ll need to set up your Storage Account based on your project needs, but one crucial step to pay attention to is enabling the Hierarchical Namespace. This setting is what transforms your storage into Azure Data Lake Storage Gen2.
Without enabling it, your account will function as a regular blob storage, and you won’t be able to create directories and folders inside your containers — which is essential for structured data organization in most data engineering workflows.
Be sure to check this option before reviewing and creating your storage account.
Once you’ve completed the setup, click on Review + Create to finalize the creation of your storage account. It may take a few minutes for the deployment to complete.
Common Mistakes to avoid
- Forgetting to enable Hierarchical Namespace (essential for Data Lake Gen2 features).
- Choosing a region far from your primary users, leading to slower performance.
- Using unclear names for Resource Groups or storage containers, making management harder later.
After your storage account is successfully deployed, the next step is to create a container — this is where we’ll store our raw and processed data. Follow the steps shown in the image below to create your first container.
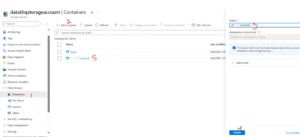
Click on the container you just created, then go ahead and add a directory. Think of a directory as a folder where your ingested data will reside — this can also be referred to as your raw zone or landing zone.
As you can see in the image below, I’ve created two directories: one named landing_zone and another called cohort_6. For this project, I’ll be uploading my CSV files into the cohort_6 folder.
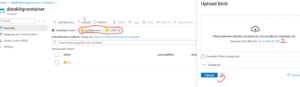
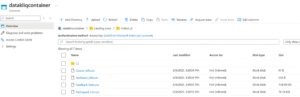
We’ve successfully created and ingested our data into the Azure Storage Account. The next step is to provision our Azure SQL Database, which we’ll use for performing data transformations.
However, before we can connect Azure Data Lake Gen 2 to Azure SQL Database, we need a connector between these two services. That’s where Azure Data Factory comes in. It acts as a bridge, allowing us to migrate data from the Gen 2 storage into the Azure SQL Database using Linked Services to establish secure and efficient connections.
In this first series, we laid a strong foundation for our Azure Data Engineering journey. We successfully created a Resource Group, provisioned an Azure Data Lake Gen 2 Storage Account, and ingested raw data into structured directories. We also discussed the importance of a landing zone and how Azure Storage serves as the backbone for modern data workflows.
In Series 2, we’ll connect our Azure Data Lake Gen 2 to Azure SQL Database through Azure Data Factory, build our first data pipeline, and transform raw data into a business-ready format.
If you don’t want to miss it, follow Onyx Data where we share step-by-step Azure, Microsoft Fabric, Databricks, and Power BI tutorials.
Authored by: