Architecting Enterprise-Grade RAG Systems: Mastering the Azure AI Ecosystem


Architecting Enterprise-Grade RAG Systems: Mastering the Azure AI Ecosystem
Businesses are increasingly looking to harness the power of large language models (LLMs) to transform how they operate, but many struggle with implementing solutions that truly deliver on the promise of AI. Retrieval Augmented Generation (RAG) has emerged as a critical approach for grounding LLMs in an organization’s proprietary information, yet most implementations today fall short of their potential.
The difference between a mediocre RAG system and one that drives genuine business value often comes down to architecture, implementation details, and a deep understanding of both the Azure ecosystem and the nuances of language models. This post explores how to build truly exceptional RAG solutions using Microsoft Azure’s comprehensive suite of tools and services.
The Current State of RAG: Promise vs. Reality
Most RAG implementations today follow a deceptively simple pattern: documents are stored, chunked, embedded, and retrieved when a user asks a question. But this oversimplified approach leads to numerous challenges:
- Retrieval failures where the system cannot find relevant information despite it existing in the knowledge base
- Hallucinations where the LLM confidently presents incorrect information
- Context limitations that prevent comprehensive understanding of complex documents
- Slow response times that frustrate users and limit adoption
- Poor document understanding that fails to capture the nuance and structure of business information
Organizations implementing basic RAG architectures quickly discover these limitations, leading to disappointment and skepticism about AI’s business value. The good news? Azure’s ecosystem offers everything needed to overcome these challenges.
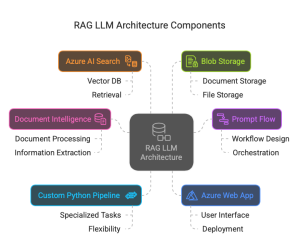
Azure’s Comprehensive RAG Ecosystem
Microsoft Azure provides a richly integrated set of services that, when properly orchestrated, can deliver RAG solutions that truly transform business operations:
Document Intelligence: The Foundation of Document Understanding
Azure Document Intelligence (formerly Form Recognizer) goes far beyond simple text extraction. This sophisticated service:
- Preserves the hierarchical structure of documents, maintaining the relationship between headings, paragraphs, and content sections.
- Accurately extracts tables while maintaining cell relationships and header contexts.
- Identifies key fields through pre-built models for invoices, receipts, IDs, and more.
- Enables custom model training for organization-specific document types.
- Recognizes document layout elements including page numbers, headers, footers, and annotations.
- Supports multiple languages and handles complex formatting without losing semantic information.
This deep document understanding forms the foundation of superior RAG systems. Rather than treating documents as undifferentiated text, Document Intelligence allows your system to understand what parts of a document are most important and how different sections relate to each other.
Azure AI Search: Beyond Basic Vector Storage
Azure AI Search has evolved into a sophisticated hybrid search service that combines traditional keyword-based retrieval with vector similarity search:
- Supports multiple vector fields with different dimensions and similarity algorithms
- Enables hybrid retrieval that combines keyword filtering with semantic search
- Provides powerful filtering capabilities based on metadata
- Implements efficient vector indexing with Hierarchical Navigable Small World (HNSW) algorithm
- Supports multi-stage retrieval workflows with filtering, vector search, and reranking
- Scales seamlessly to handle billions of vectors while maintaining query performance
- Integrates with Azure OpenAI Service for end-to-end RAG solutions
The hybrid nature of Azure AI Search allows for sophisticated retrieval strategies that balance precision and recall, dramatically improving the quality of information fed to the LLM.
Prompt Flow: Orchestrating the RAG Workflow
Building effective RAG solutions requires coordinating multiple steps and components. Azure Prompt Flow provides a visual development environment for designing, testing and deploying LLM workflows:
- Visually design end-to-end flows connecting data sources, processing steps, and LLM interactions
- Compare different prompt strategies through systematic evaluation
- Create reusable components for common RAG patterns
- Test and evaluate with real user queries to measure effectiveness
- Integrate monitoring and logging for production deployments
- Implement A/B testing frameworks to continuously improve performance
- Deploy flows as REST endpoints for integration with applications
Prompt Flow transforms RAG development from a coding exercise to a visual design process, accelerating development while improving transparency and maintainability.
Custom Python Pipelines: Ultimate Flexibility
For organizations needing complete control over their RAG implementation, Azure supports custom Python pipelines that can be deployed in various compute environments:
- Implement domain-specific chunking strategies based on document structure
- Create custom embedding approaches optimized for specific content types
- Design specialized tokenization techniques for technical terminology
- Build advanced reranking models to improve retrieval precision
- Implement feedback loops that learn from user interactions
- Integrate with existing ML workflows and data processing pipelines
- Deploy as containerized services using Azure Container Apps or AKS
This flexibility ensures that even the most demanding RAG requirements can be met within the Azure ecosystem.
Blob Storage: Secure and Scalable Document Repository
At the foundation of any RAG system is document storage. Azure Blob Storage provides:
- Virtually unlimited storage capacity with tiered access options for cost optimization
- Strong security controls including encryption, access policies, and private endpoints
- Versioning capabilities to track document changes over time
- Content hashing for document integrity verification
- Integration with Azure Active Directory for identity-based access control
- Event-based triggers for automatic processing of new documents
- Geo-redundancy options for high availability
This robust storage layer ensures that your RAG system’s document foundation is secure, scalable, and highly available.
Azure Web App: The User Interface Layer
Delivering RAG capabilities to users requires an intuitive interface. Azure Web App provides:
- Scalable hosting for custom user interfaces
- Integration with Azure Active Directory for secure authentication
- Support for real-time communication through WebSockets for interactive experiences
- Global distribution through Azure Front Door for low-latency access
- Easy deployment through CI/CD pipelines
- Monitoring and analytics to track usage patterns
- Adaptive rendering for mobile and desktop experiences
A well-designed user interface dramatically impacts adoption and effectiveness of RAG solutions, making Azure Web App a critical component of the overall architecture.
Architectural Patterns for Superior RAG Solutions
Building truly exceptional RAG systems requires moving beyond the basic architecture to implement sophisticated patterns that address common limitations:
- Hierarchical Document Processing
Rather than treating documents as flat text to be chunked arbitrarily, advanced RAG systems preserve document structure:

This hierarchical approach allows for:
- Creating multiple embedding types for different structural elements
- More precise retrieval based on document structure
- Better preservation of context during retrieval
- Improved answer synthesis by understanding structural relationships
Implementing this pattern requires using Document Intelligence to extract structure, custom processing to maintain hierarchical relationships, and specialized storage in Azure AI Search.
- Multi-Vector Representation
Instead of representing documents with a single embedding vector, advanced RAG systems use multiple vectors per document or chunk:
- Dense vectors for semantic meaning
- Sparse vectors for keyword representation
- Specialized vectors for different aspects (technical content, business impact, etc.)
- Summary vectors that capture the essence of larger sections
Azure AI Search supports multiple vector fields per document, enabling this sophisticated approach without complex custom infrastructure.
- Multi-Stage Retrieval
Rather than a single retrieval step, advanced RAG systems implement multi-stage retrieval:
- Filtering Stage: Use metadata and keywords to create a candidate set
- Retrieval Stage: Apply vector search to find semantically relevant candidates
- Reranking Stage: Apply more sophisticated (and computationally intensive) ranking to the top candidates
- Contextual Assembly: Determine which retrieved content should be included in the LLM context and in what order
This approach dramatically improves retrieval accuracy while maintaining performance at scale.
- Adaptive Chunking
Moving beyond fixed-size chunking, adaptive approaches consider:
- Natural document boundaries like paragraphs, sections, and pages
- Semantic coherence to avoid splitting related content
- Information density to adjust chunk size based on content complexity
- Query-time recombination to assemble chunks based on specific questions
Implementing adaptive chunking requires custom Python processing that analyzes document structure and content, but the investment pays dividends in retrieval quality.
- Prompt Engineering for Context Integration
The effectiveness of a RAG system ultimately depends on how well the LLM uses retrieved information. Sophisticated prompt engineering techniques include:
- Instructing the model on how to evaluate and use retrieved information
- Providing metadata about each retrieved chunk (source, date, confidence)
- Implementing reasoning steps that explicitly evaluate information relevance
- Including specific instructions for handling contradictions or information gaps
Azure OpenAI Service supports complex prompts with substantial context windows, enabling these advanced prompting techniques.
Implementation Blueprint: Building a Complete Azure RAG Solution
Translating these architectural patterns into a concrete implementation involves several key stages:
Stage 1: Document Processing and Knowledge Base Creation
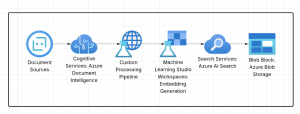
This stage involves:
- Document Collection and Preparation
- Establish connections to document sources (SharePoint, databases, file shares)
- Implement document filtering and selection logic
- Set up change detection for incremental processing
- Document Analysis with Azure Document Intelligence
- Configure pre-built models for common document types
- Train custom models for organization-specific documents
- Extract text, structure, tables, and key fields
- Hierarchical Processing
- Identify document structure (sections, subsections, etc.)
- Preserve formatting and layout information
- Extract metadata (authors, dates, categories)
- Adaptive Chunking
- Implement natural boundary detection (paragraphs, sections)
- Calculate information density to guide chunk size
- Generate overlapping chunks to preserve context
- Maintain parent-child relationships between chunks
- Multi-Vector Embedding Generation
- Generate semantic embeddings using Azure OpenAI embeddings
- Create specialized embeddings for different content aspects
- Produce summary embeddings for larger sections
- Store raw text and processed chunks in Blob Storage
- Azure AI Search Index Creation
- Design index schema with multiple vector fields
- Configure HNSW parameters for performance optimization
- Define filterable metadata fields
- Implement batch indexing for efficiency
Stage 2: Retrieval Pipeline Development
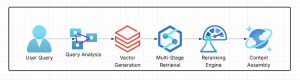
This stage involves:
- Query Analysis
- Implement intent detection to understand query type
- Extract key entities and concepts
- Identify temporal aspects (current state vs. historical information)
- Determine appropriate search strategy based on query characteristics
- Multi-Stage Retrieval
- Implement metadata filtering to narrow search space
- Configure hybrid retrieval using both keywords and vectors
- Design recall-oriented first stage to gather candidate chunks
- Create precision-oriented reranking to identify best matches
- Context Assembly
- Develop algorithms to select which chunks to include in context
- Implement deduplication to remove redundant information
- Create context ordering logic to present information coherently
- Add source attribution and confidence signals
- Integration with Azure Prompt Flow
- Design flows for different query types and business scenarios
- Implement evaluation metrics to measure retrieval effectiveness
- Create visualization components for debugging and optimization
- Deploy flows as production endpoints
Stage 3: LLM Integration and Response Generation
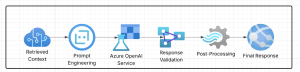
This stage involves:
- Advanced Prompt Engineering
- Design system prompts that instruct the LLM on how to use retrieved information
- Implement reasoning frameworks that guide the model through analysis steps
- Create specialized prompts for different query types and domains
- Include metadata about sources and confidence levels
- Azure OpenAI Service Integration
- Select appropriate models based on task complexity
- Configure temperature and other parameters for different scenarios
- Implement streaming responses for better user experience
- Optimize token usage to balance cost and performance
- Response Validation
- Check for hallucinations by comparing to retrieved context
- Verify factual consistency across the response
- Implement fallback mechanisms for low-confidence responses
- Add source citations to support assertions
- Post-Processing and Enhancement
- Format responses for readability and clarity
- Add visual elements for complex information
- Include references to source documents
- Provide confidence indicators for different response components
Stage 4: User Interface and Experience
This stage involves:
- Responsive Web Interface
- Design intuitive chat and search interfaces
- Implement responsive layouts for mobile and desktop
- Create visualization components for complex information
- Support document preview and exploration
- Authentication and Security
- Integrate with Azure Active Directory for identity management
- Implement role-based access control for sensitive information
- Create audit logging for compliance requirements
- Ensure data encryption throughout the pipeline
- Conversation Management
- Support multi-turn conversations with context preservation
- Implement conversation history for reference and continuity
- Create topic detection for grouping related queries
- Enable proactive suggestions based on conversation flow
- Feedback and Continuous Improvement
- Design explicit feedback mechanisms (thumbs up/down, ratings)
- Implement implicit feedback collection (query reformulation, abandonment)
- Create annotation tools for training data creation
- Build analytics dashboards for system performance monitoring
Real-World Performance Optimization
Theoretical architecture is important, but practical implementation requires addressing real-world concerns:
Latency Management
Users expect fast responses, requiring optimization throughout the stack:
- Asynchronous Processing: Implement background indexing and updates
- Caching Strategies: Cache frequent queries and their results
- Progressive Loading: Show partial results while full processing completes
- Query Optimization: Analyze and optimize slow queries in Azure AI Search
- Compute Scaling: Implement auto-scaling for variable workloads
Cost Optimization
RAG systems involve multiple Azure services, each with cost implications:
- Tiered Storage: Move older documents to cooler storage tiers
- Embedding Pooling: Batch embedding generation for efficiency
- Index Pruning: Remove outdated or irrelevant content
- Query Optimization: Reduce token usage through precise context selection
- Compute Right-Sizing: Match compute resources to actual workloads
Security and Compliance
Enterprise RAG systems must meet stringent security requirements:
- Data Encryption: Ensure encryption at rest and in transit
- Access Controls: Implement document-level security filtering
- PII Detection: Identify and handle personally identifiable information
- Audit Logging: Track all system accesses and actions
- Compliance Documentation: Generate reports for regulatory requirements
Measuring Success: RAG Evaluation Framework
Building a great RAG system requires continuous evaluation and improvement:
Retrieval Metrics
- Recall@K: Percentage of relevant documents retrieved in top K results
- Mean Reciprocal Rank: Average position of first relevant document
- Normalized Discounted Cumulative Gain: Relevance-weighted ranking evaluation
Answer Quality Metrics
- Faithfulness: Consistency of response with retrieved documents
- Relevance: Alignment of response to user query
- Completeness: Coverage of important aspects of the query
- Conciseness: Appropriate length and focus of response
User Experience Metrics
- Satisfaction Ratings: Explicit user feedback on response quality
- Task Completion Rate: Percentage of queries that resolve user needs
- Time to Resolution: Speed at which users reach their goals
- Retention and Usage: Ongoing adoption and engagement with the system
Future Directions: The Evolution of Azure RAG
The RAG landscape continues to evolve rapidly, with several emerging trends:
Multi-Modal RAG
Extending beyond text to include:
- Image understanding and retrieval
- Video content indexing and search
- Audio transcription and analysis
- Chart and graph interpretation
Azure’s cognitive services are rapidly advancing in these areas, enabling truly multi-modal RAG experiences.
Agentic RAG
Moving beyond passive retrieval to active information gathering:
- Query decomposition into sub-questions
- Autonomous exploration of knowledge bases
- Dynamic reasoning about information needs
- Tool use to gather additional information
Azure’s AI orchestration capabilities are laying the groundwork for these agentic systems.
Personalized RAG
Tailoring responses based on user context:
- Learning from interaction history
- Adapting to user expertise levels
- Personalizing information presentation
- Building user-specific knowledge models
Azure’s identity and personalization services enable these tailored experiences while maintaining privacy and security.
Conclusion: Building RAG Solutions That Deliver Real Business Value
Creating truly exceptional RAG solutions within the Azure ecosystem requires moving beyond basic implementations to sophisticated architectures that address the full spectrum of challenges:
- Document understanding that preserves structure and meaning
- Intelligent retrieval that balances precision and recall
- Context-aware prompting that guides the LLM effectively
- User experiences that deliver information intuitively
- Continuous improvement through systematic evaluation
Organizations that invest in this comprehensive approach will unlock the true potential of RAG systems, transforming how they leverage their knowledge assets and interact with customers and employees.
The Azure ecosystem provides all the components needed to build these sophisticated systems, from Document Intelligence for deep document understanding to Prompt Flow for workflow orchestration. By combining these services with thoughtful architecture and continuous optimization, businesses can create RAG solutions that truly deliver on the promise of AI-powered information access.
Related Articles


